This post is part of a series of posts about CloudRAID. The predecessor can be found here. The successor can be found in Markus Holtermann’s blog.
3.3.3 Database Design
CloudRAID uses – as described above – an HSQL database for storing meta data of split files and information of user accounts. The database design can be very simple since the server application does not need much information. The database consists of two tables – one table to store the user accounts, one to store the file metadata (see Figure 14 on page 24). The cloudraid users table stores a unique user ID, a unique user name, the encrypted password, and a salt needed to encrypt the password securely. The cloudraid files table stores a unique file ID, a path name (which is the file name), a hash of the path name (used to name the files uploaded to the cloud storage services), the date of the last upload of this file, the file’s status, and the user ID of the user the file belongs to (which is a foreign key to the cloudraid users table’s ID column). The user ID together with the path name is the unique key of this table. Between both tables exists an n:1 -relationship – n files belong to 1 user, a file cannot belong to more than one user.
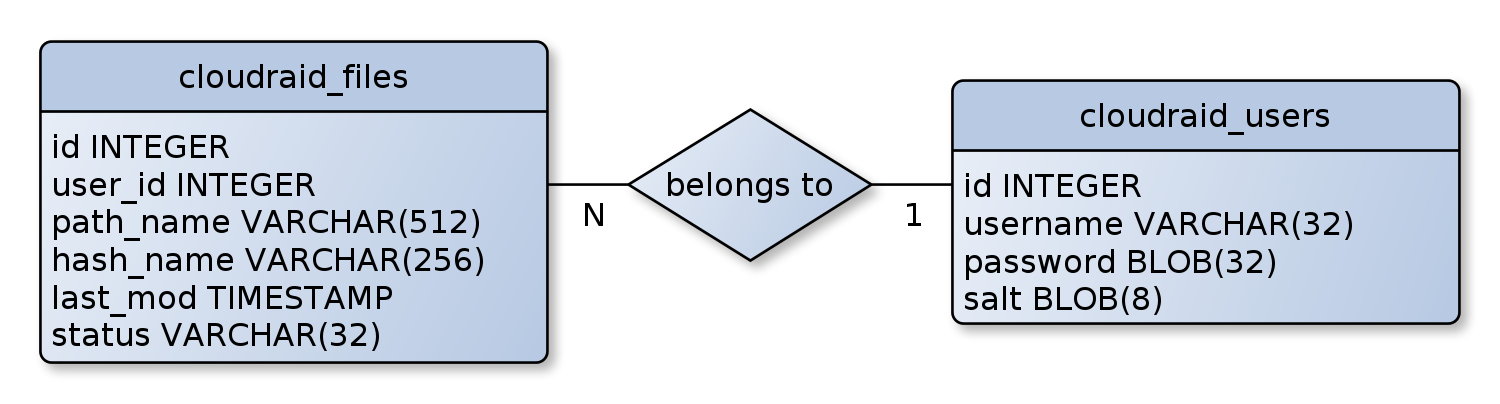 Figure 14: Database design of the CloudRAID HSQLMetadataManager.
Figure 14: Database design of the CloudRAID HSQLMetadataManager.
Since core and RESTful need file information but they should not make any assumptions about how a Java ResultSet looks like all file datasets from cloudraid files are transferred into an object representation. This object representation is defined by the ICloudFile interface in the interfaces bundle (see listing 2 on page 24). The actual implementation of ICloudFile is done in the regarding metadatamanager bundle and can be dependent on the database or other storage form.
 Listing 2: The ICloudFile interface.
Listing 2: The ICloudFile interface.
Core and RESTful also need a way to retrieve ICloudFiles, and register new users and files. This is done via the IMetadataManager service. The IMetadataManager is defined as shown in listing 3 on page 25.
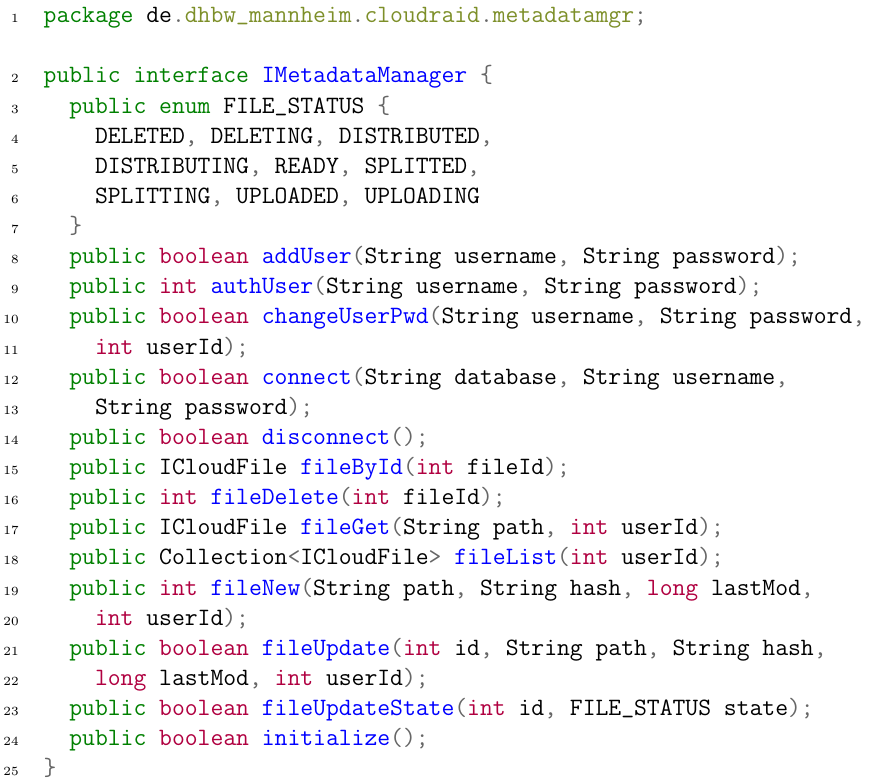 Listing 3: The IMetadataManager interface.
Listing 3: The IMetadataManager interface.
General methods are the connect() and the disconnect() method. They are the first, respectively last method that is called. Another general method is initialize(); after connecting to a database, this method is called to ensure that there are all relevant database tables with correct constraints and dependencies in the database. The authUser() method checks, if a user tried to authorize with the correct credentials. If so, it returns the unique ID of this user – which is then used for other method calls to identify the user – else, it returns -1. addUser() creates a new user in the database and returns true, if the creation was successful. Most of the file-related methods have self-explanatory names. fileById() gets the file representation of a file whose ID is known while fileGet() returns the file representation when the owner and the path name are known.
3.3.4 Server API
As described in chapter 3.3.1 – Core on page 20, the interface between CloudRAID client and server software is implemented as a RESTful API. The advantages are that it is based on the well-known HTTP protocol and can easily be implemented using OSGi bundles shipped with Equinox. Caused by the modularity of the CloudRAID server application further APIs can be implemented. Another API could be for example a WebDAV19 API. The API implementation has only to get the Core bundle’s ICoreAccess service implementation (for ICoreAccess see listing 4 on page 26). The putData() methods are used to send file data from the API to the Core bundle. The methods getData() and finishGetData() are used to send file data from the Core bundle to the API. deleteData() sends the deletion request for a certain file to the Core bundle. reset() resets the internal state of the ICoreAccess implementation.
 Listing 4: The ICoreAccess interface.
Listing 4: The ICoreAccess interface.
3.3.5 Java Native Interface
An important decision when designing the server application was to implement the RAID functionality in the C programming language and to include it via the Java Native Interface. To use JNI the developer defines “native” methods in Java classes. These native methods are similar to abstract methods; they also have no function bodies – the bodies are implemented by the external C (or C++) libraries. In a class that defines native methods the C library has to be loaded. Using the javah command that ships along with the Java Software Development Kit (SDK) a C header file is generated that defines the function signatures for the implementations of the native methods in the Java class. A big advantage of JNI is that performance critical software parts can be executed faster since programs written in the C programming language are mostly much faster, especially regarding hardware access (disk I/O) or handling data on bit level. The decision for using JNI was taken because of some tests and benchmarks comparing a Java, Python and C implementation of a RAID level 5 functionality (see chapter 6.2 – Comparison of Java, Python and C on page 55). But using JNI has also some disadvantages: The C code may not be platform independent. This means that slightly different implementations must be developed for Unix and Microsoft Windows machines. Additionally, JNI can be a source of memory leaks; but the chance of a memory leak can be reduced by good code and suitable software tests. Balancing the disadvantages against the much higher speed and therefore much shorter runtime vindicates the potential memory leaks, from our point of view.
3.3.6 RAID and Encryption Design
Given that CloudRAID should provide redundancy of the stored data, various RAID levels have been considered that have been introduced in chapter 2.3 – Background on RAID Technology on page 12. Justified by the requirement for high data throughput and a minimum of additionally space for redundancy requirements we made the decision to use RAID level 5, based on the facts that are shown in the same place too. As underlying cryptographic algorithm RC4 is used. This decision was made because this algorithm is used in acquainted environments like the BitTorrent protocol20, the Secure Socket Layer (SSL) and Microsoft Point-To-Point Encryption (MPPE) protocol21. Besides that, a stream cipher can more easily handle various lengths of bytes than a block cipher which would require a proper padding of the input. Furthermore, RC4 has been chosen because of its simplicity and speed, both during key setup and the encryption and decryption calls. As shown in figures 2 and 3 of [PK01] and in all diagrams and tables shown in [NS11], is much faster and much more efficient than a common block cipher like AES and furthermore its speed is independent of the key size. The cipher key should be enhanced by a salt because this will makes the whole cipher key more secure and unpredictable. The usage of Message Authentication Codes (MACs) or Hash-based Message Authentication Codes (HMACs) can be reasonable and would lead to the desired security. The encryption and decryption integration into the RAID split and merge processes is directly after reading the original input file during split and right before writing the merged data to the output file. This simplifies and speeds up both processes many times. First of all, only one key needs to be managed because the split and merge is done with the encrypted data. There is no “part” or “device”-related encryption. This leads to the decreased runtime, since there is only one key setup done before starting the split or merge.
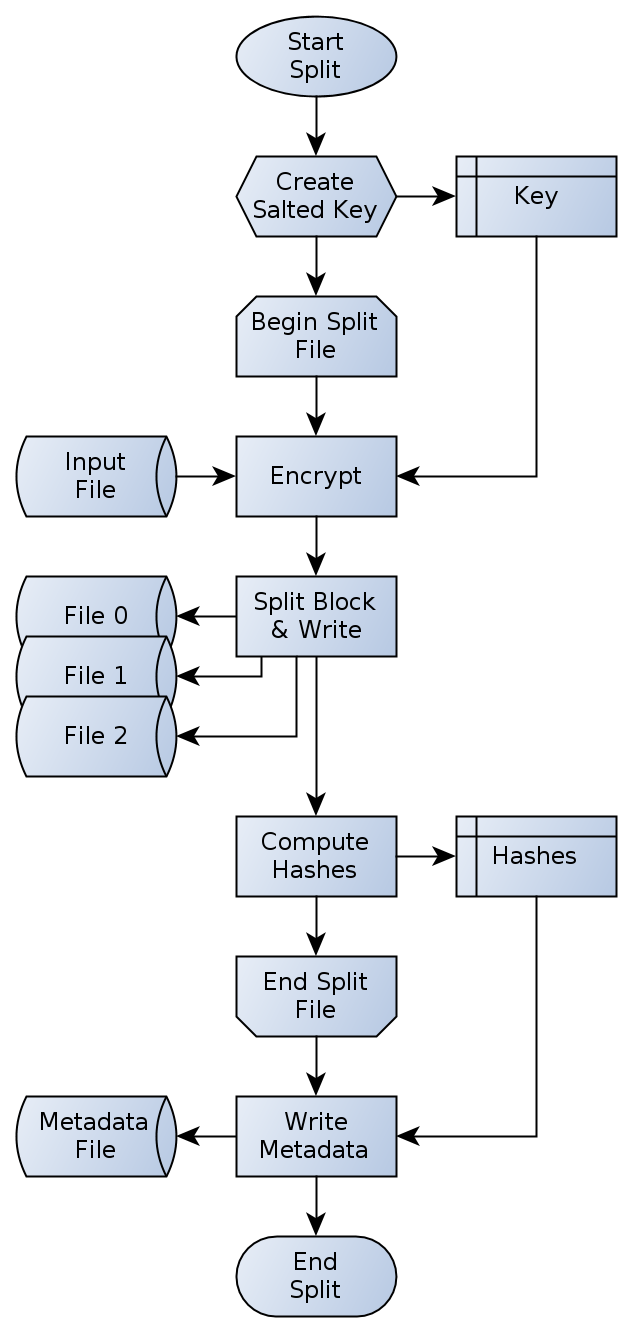 Figure 15: Split process operation flowchart
Figure 15: Split process operation flowchart
The split process of a file uploaded to the CloudRAID service will basically read the file block-wise with twice the internal RAID block-size, split the file into three parts (each having at most the internal block-size size) and finally writes the parts to the device files. By continuously changing the position of the parity, the effect of moving it over all devices, can be achieved. Hence the mentioned bottleneck will not occur that likely. The diagram alongside shows the process operation for the complete split process. To provide a high encrypted strength, the split process must generate a random salt. The better the randomness of the salt is the higher the encryption level is due to the concept and implementation of RC4. The salt is combined with a given key and therefore a high confidentiality can be accomplished. After the full key has been generated, the input file is read block-wise. Every block that is read will first be encrypted and split after that. During reading the input file and writing the parts to the device files, the check sums for the three device files and for the input file will be computed. Since the Secure Hash Algorithm (SHA)-2 function is generally capable handling this kind of iterative updates of the hashing context, a second file access on all of the four files is not necessary. As a matter of course, this will reduce the time to complete the split process by a huge amount of time. The last but not less essential part of the overall split process is depicted in the final process box: writing the meta data. The meta data file will contain a lot of information about how the data is organized in the device files. Besides the check sums, the salt will be kept there.
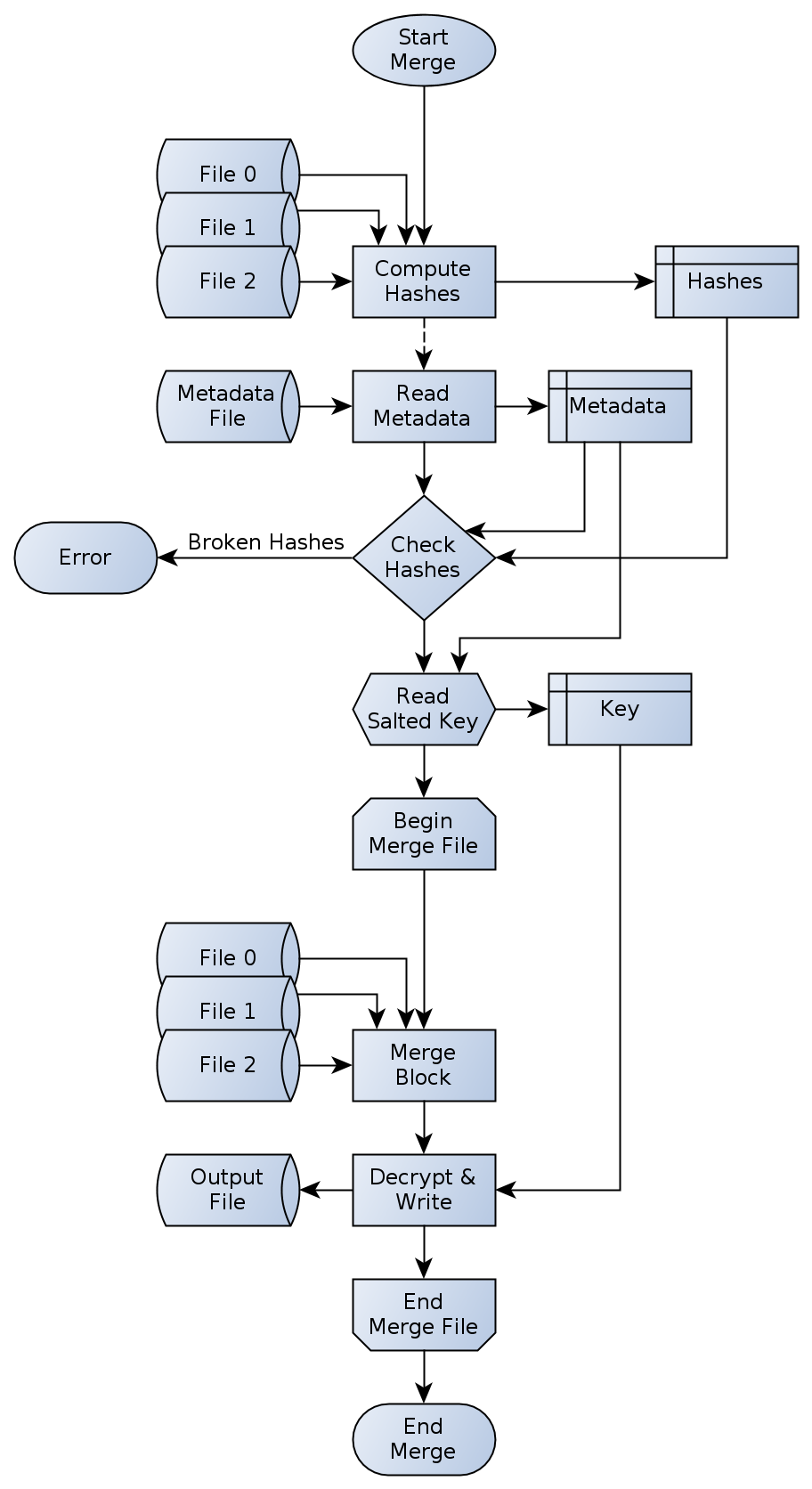 Figure 16: Merge process operation flowchart
Figure 16: Merge process operation flowchart
The merge process is the reverse to the split process. It will take two to three device files and merge them together, leading to the final output file. In contrast to the split process, the merge process is much more complicated and time expensive at the first glance. As one can see in figure 16 on page 29 there are two read accesses to the device files. This will inevitably increase the runtime. But nevertheless, both read accesses are necessary in order to provide data integrity checks. The check sums of the device files must be calculated before any actual merge of these files may happen. Taking the computed hash sums and comparing them with the hash sums from the given meta data file will show any inconsistency of broken device files. If more than one hash is incorrect, and therefore no successful merge will be possible, the merge process must stop. In other cases, if at least two hash sums are valid, the actual merge is going to start. As the salt used to enhance the key must be taken from the meta data, the complete key for decryption must be generated. Afterwards the data is read from the three device files and merged into a single output. This output then needs a decryption as it has been encrypted before.
3.4 Client Architecture
Caused by the usage of the three layer architecture of the overall application the client application can have a very simple architecture. It can consist of two components:
- The network component wraps the server’s REST API. It sends requests that may contain files, interprets the HTTP response codes and handles them by throwing appropriate exceptions.
- The representation component uses the network component by giving required parameters form user inputs and handling the responses and exceptions.
Footnotes
- 19 Web-based Distributed Authoring and Versioning
- 20 https://en.wikipedia.org/wiki/BitTorrent_protocol_encryption
- 21 MPPE: https://datatracker.ietf.org/doc/html/rfc3078
References
- [NS11] J. P. S. Raina Nidhi Singhal. Comparative Analysis of AES and RC4 Algorithms for Better Utilization. International Journal of Computer Trends and Technology (IJCTT), 1(3):177 – 181, July – August 2011. http://www.ijcttjournal.org/volume-1/Issue-3/IJCTT-V1I3P107.pdf.
- [PK01] P. Prasithsangaree and P. Krishnamurthy. Analysis of Energy Consumption of RC4 and AES Algorithms in Wireless LANs, July 31, 2001. http://www.sis.pitt.edu/∼is3966/group5_paper2.pdf, Global Telecommunications Conference, 2003. GLOBECOM ’03.